MATLAB模拟碰撞
1 | m=[3,1,2];%小球质量 |
1 | m=[3,1,2];%小球质量 |
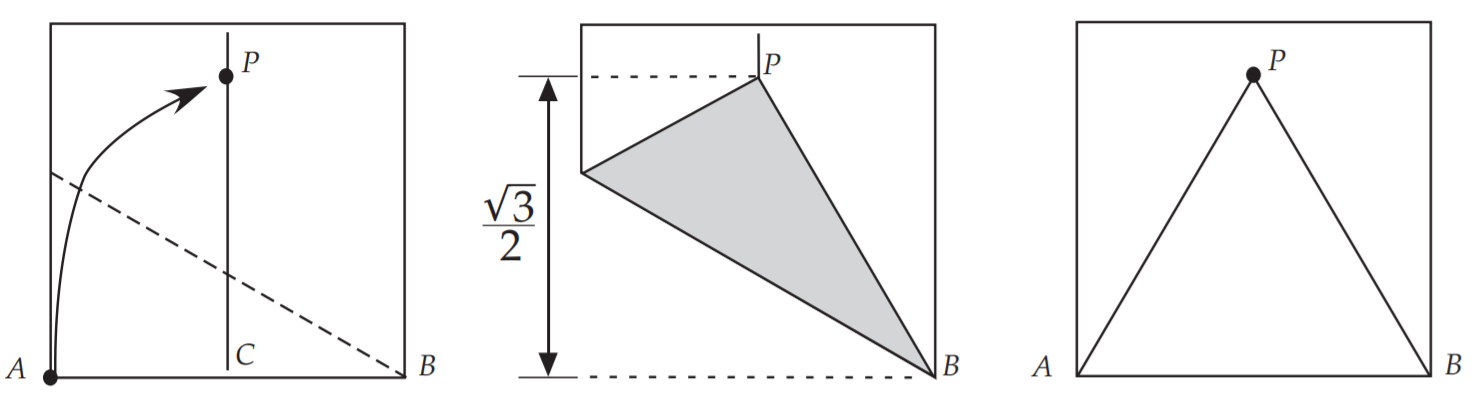
要折等边三角形,首先要折出$60{\circ}$的角,以下是最容易的一种方法
如何让三角形最大呢
所以我们只需要研究某一个顶点和正方形的顶点重合的等边三角形
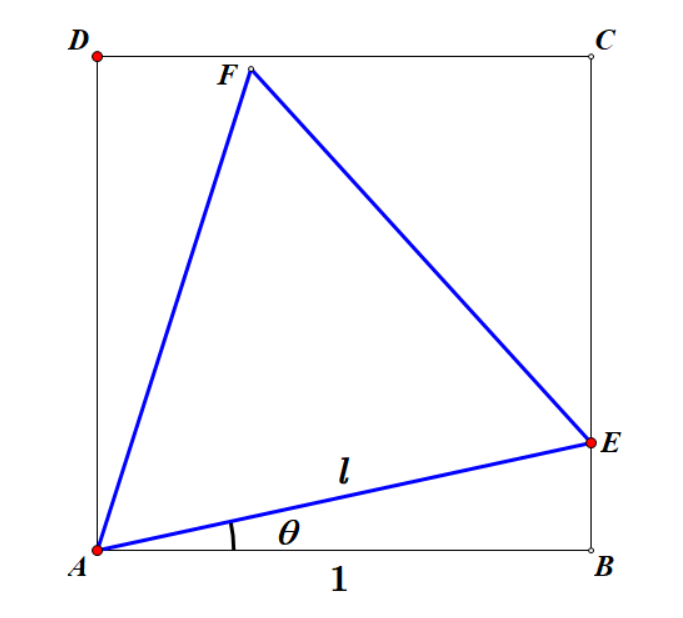
画出图形,由几何关系,三角形的边长$l$可以用$\theta$表达
$
l=1 / \cos \theta=\sec \theta
$
故面积$S$为
$
S(\theta)=\frac{\sqrt{3}}{4} \sec ^{2} \theta
$
根据对称性,我们只需要考虑$0^{\circ} \leq \theta \leq 15^{\circ}$的情况
因为$\cos \theta $在$0^{\circ} \leq \theta \leq 15^{\circ}$单调递减
所以$\sec\theta=\frac{1}{ {\cos \theta } }$在$0^{\circ} \leq \theta \leq 15^{\circ}$单调递增
或对面积求导
$
\frac{\mathrm{d}S}{\mathrm{d} \theta } =2\cdot \frac{\sqrt{3}}{4} \cdot \frac{1}{\cos\theta } \cdot -\frac{1}{\cos ^{2} \theta}\cdot
-\sin \theta =\frac{\sqrt[]{3}\sin \theta }{2\cos^{3} \theta }
$
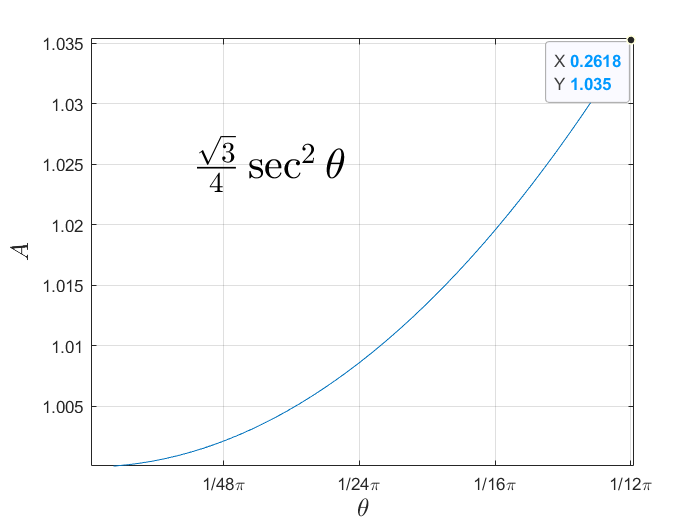
当$\theta=15^{\circ}$时有最大值
故此时$l=\sqrt{6}-\sqrt{2}=1.035$
或者用几何方法分析
$\begin{array}{l}l &=\sqrt{AB^2+BE^2} \&=\sqrt{1+BE^2}\end{array}$
当$BE$最大时边长有最大值
$\therefore\begin{array}{l}S &=\frac12l^2\sin60^\circ \&=\frac{\sqrt{3}}{4}\times(\frac{AB}{\cos15^\circ})^2\end{array}\$
由半角公式得
$\begin{array}{l}\sin15^\circ &=\sqrt{\frac{1-\sin30^\circ}{2}}\&=\frac12\sqrt{2-\sqrt3} \&=\frac12\sqrt{(\frac{\sqrt6}{2})^2-2\cdot\frac{\sqrt6}{2}\cdot\frac{\sqrt2}{2}+(\frac{\sqrt2}{2})^2} \&=\frac12\sqrt{(\frac{\sqrt6}{2}-\frac{\sqrt2}{2})^2} \&=\frac{\sqrt6-\sqrt2}{4}\end{array}$
$\begin{array}{l}\cos15^\circ &=\sqrt{\frac{1+\cos30^\circ}{2}} \&=\frac{\sqrt6+\sqrt2}{4}\end{array}$
或使用两角和与差公式$\sin(\theta\pm\phi)=\sin\theta\cos\phi\pm\cos\theta\sin\phi$有
$\begin{array}{l}\sin15^\circ &=\sin(60^\circ-45^\circ)\&=\sin60^\circ\cos45^\circ-\cos60^\circ\sin45^\circ\&=\frac{\sqrt6-\sqrt2}{4}\end{array}$
$\begin{array}{l}\cos15^\circ &=\sqrt{1-\sin15^\circ} \&=\frac{\sqrt6+\sqrt2}{4}\end{array}$
故$S=\frac{\sqrt{3}}{4}(\frac{4}{\sqrt6+\sqrt2})^2=2\sqrt3-3$

能力要求
能力是指空间想象能力、抽象概括能力、推理论证能力、运算求解能力、数据处理能力
以及应用意识和创新意识.
1.空间想象能力:能根据条件作出正确的图形根据图形想象出直观形象;能正确地分析
出图形中的基本元素及其相互关系;能对图形进行分解、组合;会运用图形与图表等手段形
象地揭示问题的本质.
空间想象能力是对空间形式的观察、分析、抽象的能力,主要表现为识图、画图和对图
形的想象能力.识图是指观察研究所给图形中几何元素之间的相互关系;画图是指将文字语
言和符号语言转化为图形语言以及对图形添加辅助图形或对图形进行各种变换;对图形的想
象主要包括有图想图和无图想图两种,是空间想象能力高层次的标志.
2.抽象概括能力:抽象是指舍弃事物非本质的属性揭示其本质的属性;概括是指把仅仅
属于某一类对象的共同属性区分出来的思维过程.抽象和概括是相互联系的,没有抽象就不可
6.应用意识:能综合应用所学数学知识、思想和方法解决问题,包括解决相关学科、生产、
生活中简单的数学问题;能理解对问题陈述的材料,并对所提供的信息资料进行归纳、整理
和分类,将实际问题抽象为数学问题;能应用相关的数学方法解决问题进而加以验证,并能用
数学语言正确地表达和说明.应用的主要过程是依据现实的生活背景提炼相关的数量关系,
将现实问题转化为数学问题,构造数学模型,并加以解决.
7.创新意识:能发现问题、提出问题,综合与灵活地应用所学的数学知识、思想方法,选
择有效的方法和手段分析信息,进行独立的思考、探索和研究,提出解决问题的思路,创造性地
解决问题.
创新意识是理性思维的高层次表现.对数学问题的“观察、猜测、抽象、概括、证明”,是
发现问题和解决问题的重要途径,对数学知识的迁移、组合、融会的程度越高,显示出的创新
意识也就越强.
个性品质要求.
个性品质是指考生个体的情感、态度和价值观.要求考生具有一定的数学视野,认识数学
的科学价值和人文价值,崇尚数学的理性精神,形成审慎的思维习惯,体会数学的美学意义.
要求考生克服紧张情绪,以平和的心态参加考试,合理支配考试时间,以实事求是的科学
态度解答试题,树立战胜困难的信心,体现锲而不舍的精神.
考查要求
数学学科的系统性和严密性决定了数学知识之间深刻的内在联系,包括各部分知识的纵
向联系和横向联系,要善于从本质上抓住这些联系,进而通过分类、梳理、综合,构建数学试卷
的框架结构.
1.对数学基础知识的考查,既要全面又要突出重点对于支撑学科知识体系的重点内容,要
占有较大的比例,构成数学试卷的主体.注重学科的内在联系和知识的综合性,不刻意追求知
识的覆盖面.从学科的整体高度和思维价值的高度考虑问题,在知识网络的交汇点处设计试题,
使对数学基础知识的考查达到必要的深度.
2.对数学思想方法的考查是对数学知识在更高层次上的抽象和概括的考查,考查时必须
要与数学知识相结合,通过对数学知识的考查,反映考生对数学思想方法的掌握程度.
3.对数学能力的考查,强调“以能力立意”,就是以数学知识为载体,从问题入手,把握学科
的整体意义,用统一的数学观点组织材料,侧重体现对知识的理解和应用,尤其是综合和灵活
的应用,以此来检测考生将知识迁移到不同情境中去的能力,从而检测出考生个体理性思维的
广度和深度以及进- 步学习的潜能.
对能力的考查要全面,强调综合性、应用性,并要切合考生实际对推理论证能力和抽象概
括能力的考查贯穿于全卷,是考查的重点,强调其科学性、严谨性、抽象性;对空间想象能力
的考查主要体现在对文字语言、符号语言及图形语言的互相转化上;对运算求解能力的考查
主要是对算法和推理的考查,考查以代数运算为主;对数据处理能力的考查主要是考查运用
概率统计的基本方法和思想解决实际问题的能力.
4.对应用意识的考查主要采用解决应用问题的形式.命题时要坚持“贴近生活,背景公平,
控制难度”的原则,试题设计要切合中学数学教学的实际和考生的年龄特点,并结合实践经验,
使数学应用问题的难度符合考生的水平.
5.对创新意识的考查是对高层次理性思维的考查.在考试中创设新颖的问题情境,构造有
一定深度和厂度的数学 问题时,要注重问题的多样化,体现思维的发散性;精心设计考查数学
主体内容、体现数学素质的试题;也要有反映数、形运动变化的试题以及研究型、探索型、
开放型等类型的试题.
数学科的命题,在考查基础知识的基础上,注重对数学思想方法的考查,注重对数学能力
的考查,展现数学的科学价值和人文价值,同时兼顾试题的基础性、综合性和应用性,重视试题
间的层次性,合理调控综合程度,坚持多角度、多层次的考查,努力实现全面考查综合数学素
养的要求,促进学生德智体美劳全面发展.
1.接受、吸收、整合化学信息的能力
(1)对中学化学基础知识能正确复述、再现、辨认,并能融会贯通。
(2)通过对自然界、生产和生活中的化学现象的观察,以及实验现象、实物、模型的
观察,对图形、图表的阅读,获取有关的感性知识和印象,并进行初步加工、吸收、有序存
储。
(3)从提供的新信息中,准确地提取实质性内容,并与已有知识整合,重组为新知识
块。
2.分析和解决化学问题的能力
(1)将实际问题分解,通过运用相关知识,采用分析、综合的方法,解决简单化学问
题。
(2)将分析和解决问题的过程及成果,能正确地运用化学术语及文字、图表、模型、
图形等进行表达,并做出合理解释。
3.化学实验与探究的能力
(1)掌握化学实验的基本方法和技能,并初步实践化学实验的- -般过程。
(2)在解决化学问题的过程中,运用化学原理和科学方法,能设计合理方案,初步实
践科学探究。
1.理解能力
(1)能理解所学知识的要点,把握知识间的内在联系,形成知识的网络结构。
(2)能用文字、图表以及数学方式等多种表达形式准确地描述生物学方面的内容。
(3)能运用所学知识与观点,通过比较、分析与综合等方法对某些生物学问题进行解
释、推理,做出合理的判断或得出正确的结论。
2.实验与探究能力
(1)能独立完成“生物知识内容表”所列的生物实验,包括理解实验目的、原理、方
法和操作步骤,掌握相关的操作技能,并能将这些实验涉及的方法和技能等进行运用。
(2)具备验证简单生物学事实的能力,能对实验现象和结果进行分析、解释,并能对
收集到的数据进行处理。
(3)具有对一些生物学问题进行初步探究的能力,包括运用观察、实验与调查、假说
演绎、建立模型与系统分析等科学研究方法。
(4)能对一些简单的实验方案做出恰当的评价和修订。
3.获取信息的能力
(1)能从提供的材料中获取相关的生物学信息,并能运用这些信息,结合所学知识解
决相关的生物学问题。
(2)关注对科学、技术和社会发展有重大影响的、与生命科学相关的突出成就及热点问
题。
4.综合运用能力
理论联系实际,综合运用所学知识解决自然界和社会生活中的一些生物学问题。
日本筑波大学生物学教授芳贺和夫(Kazuo Haga),在等待实 验结果的时候喜欢用摺纸打发时间。他发现了以下的有趣结果。
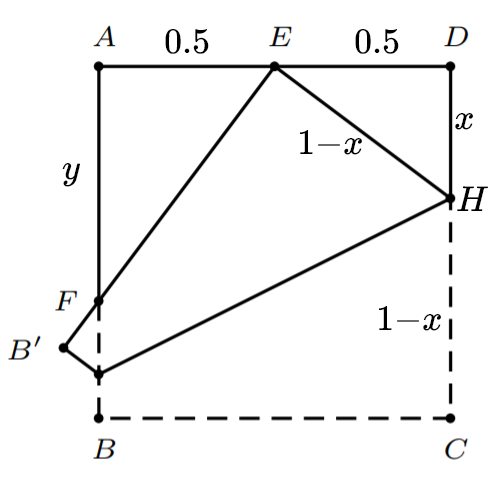
$Claim:F$为$AB$的三等分点
$proof:$
设正方形边长为1,将$C$折到$AD$的中点$E$处,由图
解得$x=\frac{3}{8}$
又$\triangle FAR \sim \triangle EDH$
解得$y=\frac{2}{3}$
$Property:$
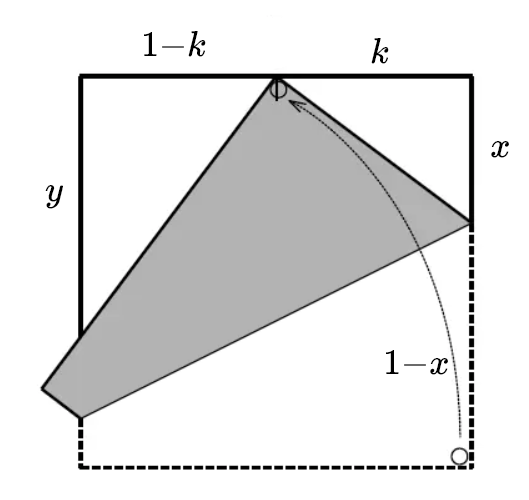
通过相似三角形和勾股定理,联立两个方程
若正方形边长为1,有$k=\frac{1}{N}$,带入得到

如果一直按此方法重复,就可以由$n$等分得到$n+1$等分,于是便得到了任意等分 有点麻烦
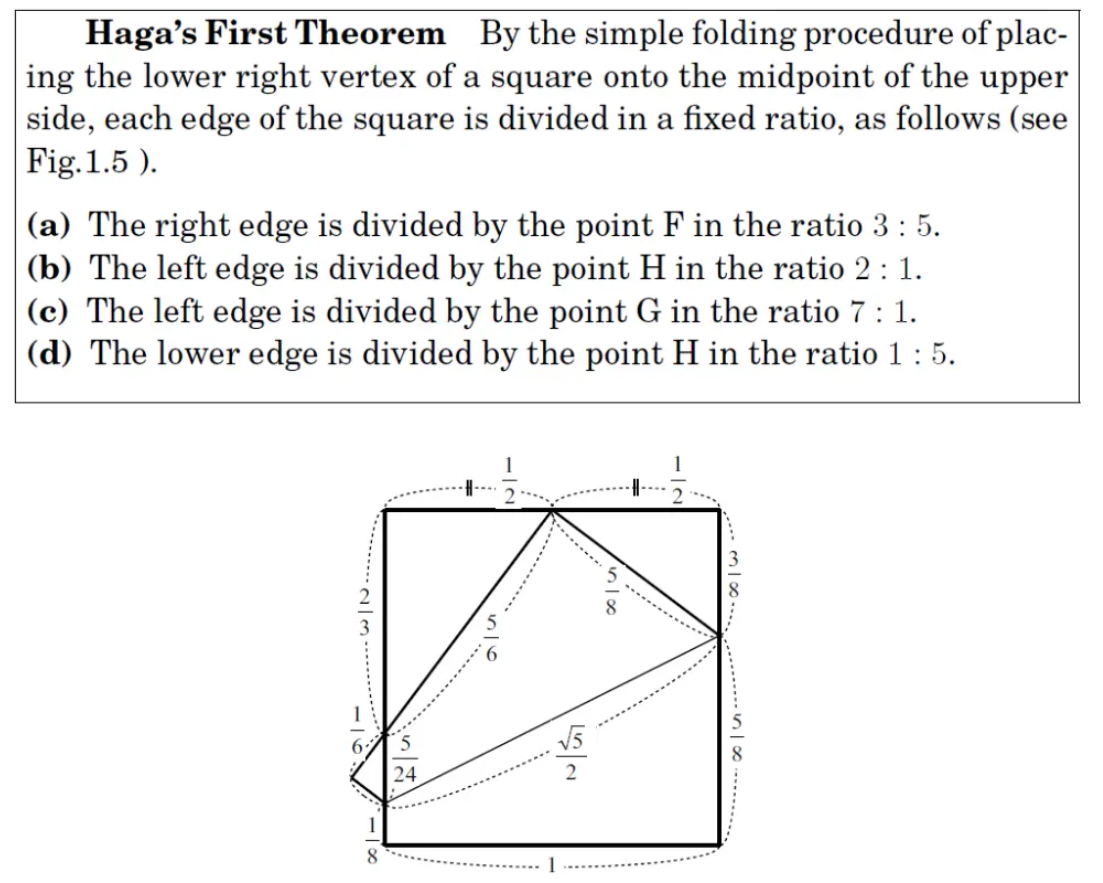 注意左上角的直角三角形,它是一个$3:4:5$的直角三角形,难道这只是巧合吗
注意左上角的直角三角形,它是一个$3:4:5$的直角三角形,难道这只是巧合吗
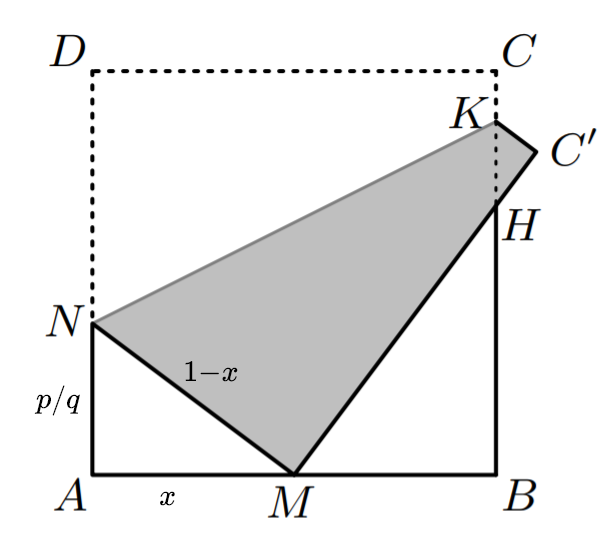
$A B=1, A N=x $及$A M=\frac{p}{q} $其 中 $p, q \in \mathbb{N}, M N=1-x $
所以,
所以只要$p$和$q$是整数,那么这三条边的比就一定是勾股数
将$AB$沿$CF$折叠,延长$FG$交$AD$于$E$
在$\triangle AEF$中,有
解得$x=\frac{1}{3}$,即$E$是$AD$的三等分点
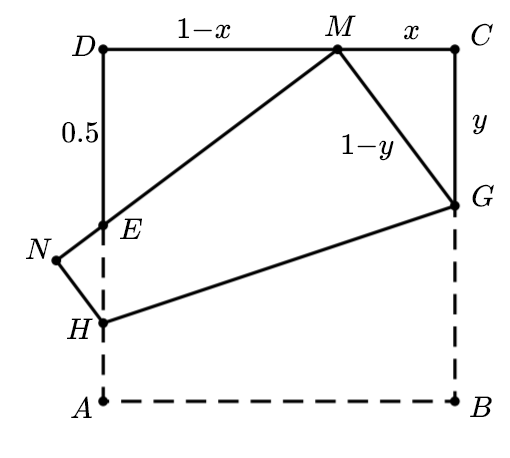
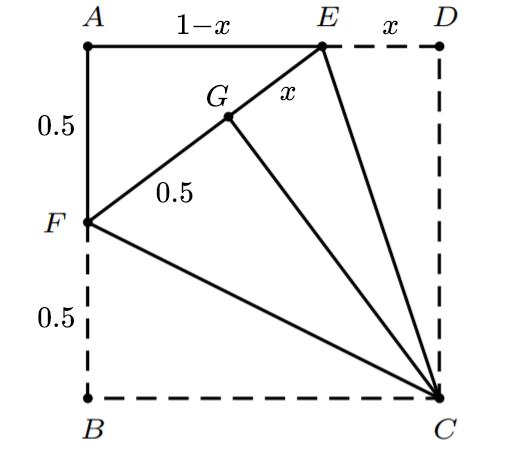
设正方形 $ABCD$的边长为1,$ C M$=$x$, $C G$=$y$
将$AB$边折到$AD$中点$E$上,并让$B$点落在$CD$上
由 $\triangle E D M \sim \triangle C M G$, 可得
在$\triangle C M G$ 中, $G M1-CG=1-y$,有
解之得
带入得$x=\frac{1}{3}$,即点$M$是$ C D $的三等分点.
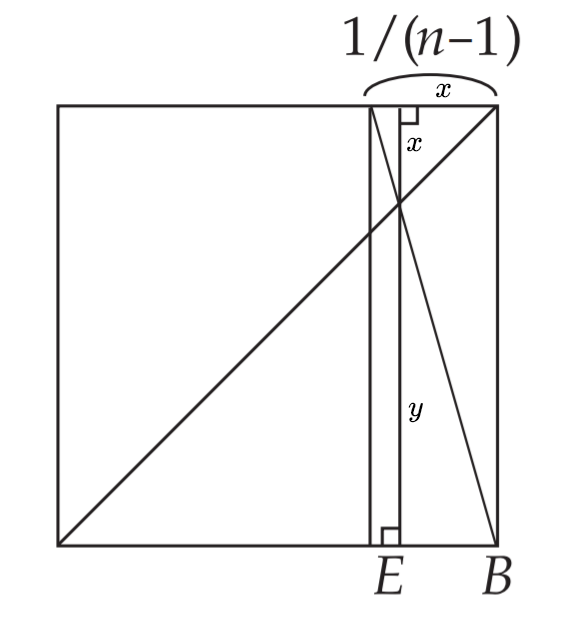
如果我们得到了$n-1$等分,在图中不难看出
消去$y$可以得到$x=\frac{1}{n}$
这样我们又有一种n等分的方式
$tip:$如果要得到7等分,我们可以先折3等分再对折,从而由6等分得到7等分
首先厘清题意明确情形
对图形进行全面有序的分析
找出所求目标(正确或错误)
分析问题将题给条件进行转换
在空白处写出关键条件
对照原题标出数据
在草稿纸上进行化简计算
对照选项进行验证
若非常有把握就直接过
有困难就排除分析
我们说样本空间是无限可数的意味着其中的元素可以与正整数一一对应
样本空间$S$上的概率分布$\rm {Pr{}}$是一个从事件到实数的映射
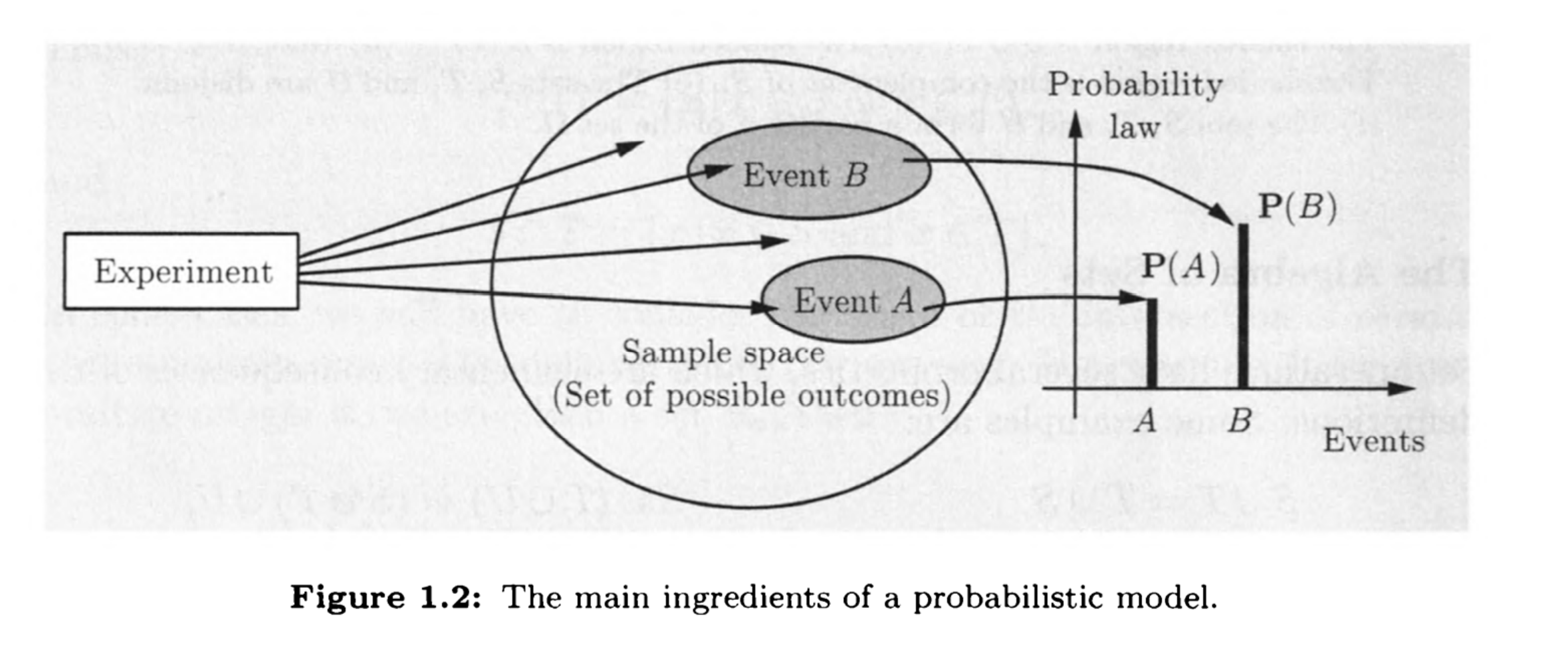
将事件$\text{Pr}({A})$简记为$\text{Pr}{A}$
事件可能有无数个,如掷硬币n次H
$\forall 事件A,\text {Pr}{A}\ge0$
$\text {Pr}{S}=1$
对两两互斥的事件,有
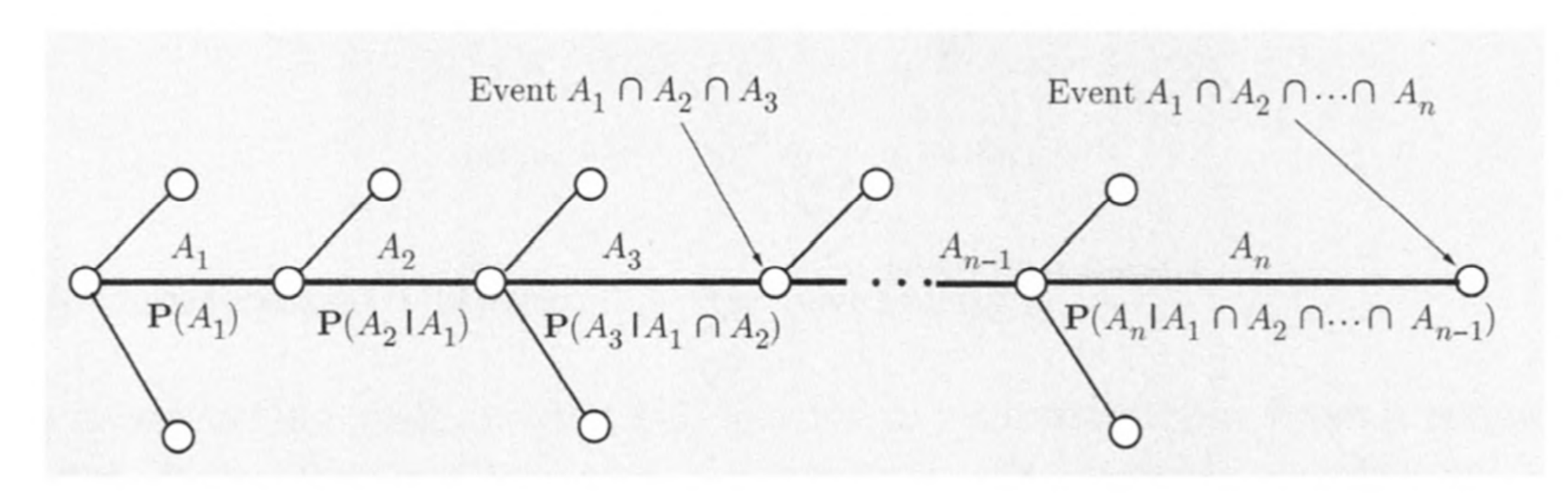
对于一个序列型的事件,可以用以下方式描述
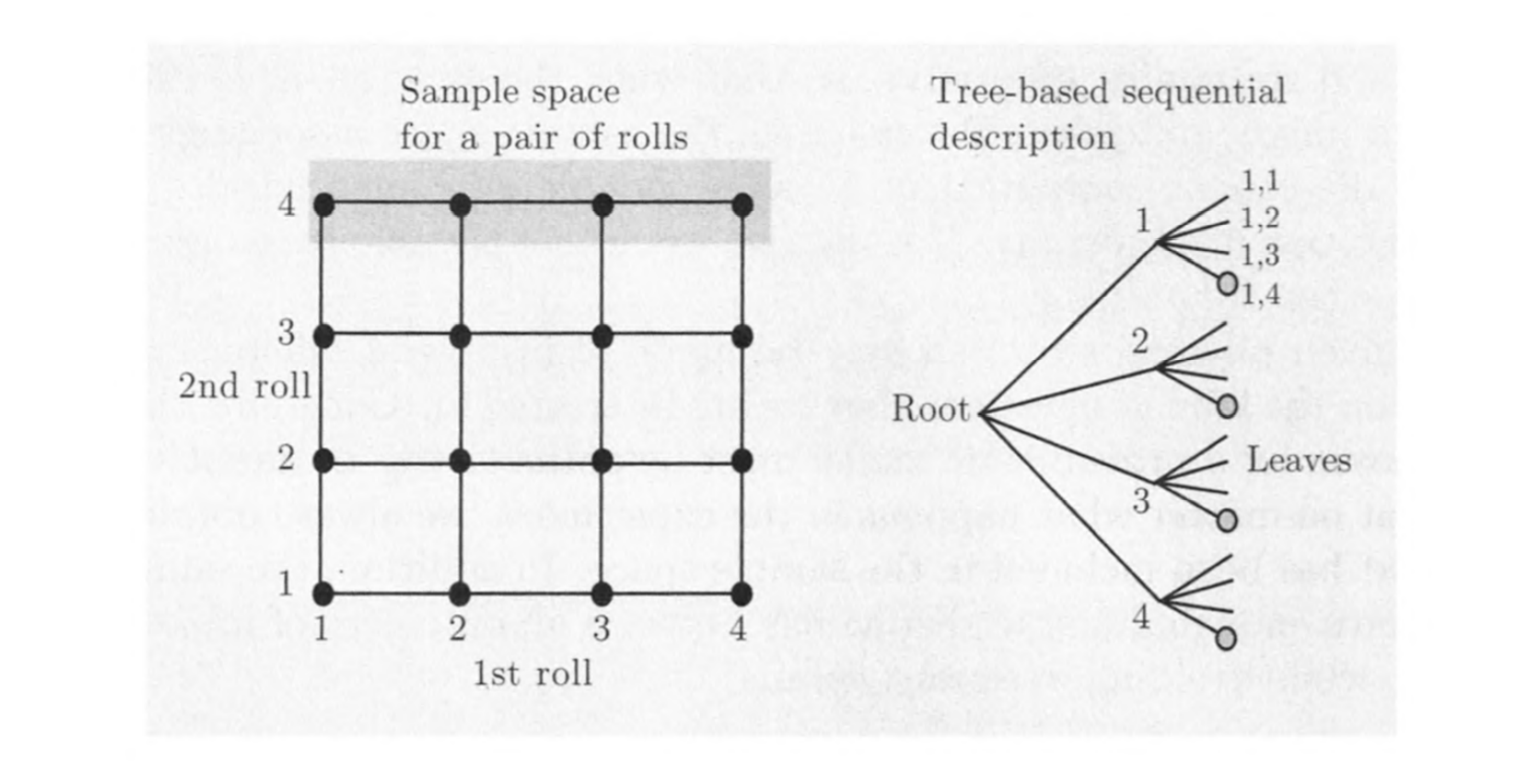
为了构建模型,我们需要考虑多个因素
The choice of a model often involves a tradeof be-tween accuracy, simplicity,and tractability.
但是不论多复杂的模型,对于某个特定的事件都有确定的概率
All conceivable questions have precise answers and it is only a matter of developing the skill to arrive at them.
对于多个等概率事件
样本空间可以用图形来表示
对于样本空间为
对于某一个值,概率为0,只有考虑长度才有意义
由德摩根律
概率分布在有限或无限可数的样本空间,则该概率分布是离散的
若基本事件$s\in S$的概率为
则称为$S$上的的均匀概率分布
已知事件 $B$发生$\text {Pr}{B}\ne 0$,事件$A$的条件概率定义为
需要从直观角度上理解
若
则称事件$A$和$B$是独立的,若$\text {Pr}{B}\ne 0$,则等价于
若对于所有$1\le i < j\le n$,有
则称事件$A_1,A_2,\cdots,A_n$两两独立
若对这些事件的每一个$k$子集${ A{i_1},A{i2},\cdots,A{i_k}}$,其中$2\le k\le n$且$1\le {i_1}< {i_2}< \cdots< {i_k}\le n $,有
则称这些事件相互独立
In words, this relation states that if is known to have occurred,the additional knowledge that B also occurred does not change the probability of A.
考虑事件A为第一次掷为H,B为第二次H,C为两次结果不同
所以独立不代表条件独立
则A,B两个独立事件不条件独立
将样本空间$\Omega$划分为两两独立的$n$个事件,且
则
由
得
对于$\Pr{B}$,因为可以划分,故
所
贝叶斯定理常常用来由果导因,如抗原阳性是否代表感染新冠
其中$\Pr{A_i|B}$为后验概率,$\Pr{A_i}$是先验概率
分类加法计数原理,同一个阶段的不同方法可以相加
有N个阶段每个阶段有$n_i$个方式,则总方式为
将n个元素分为$k$类,其中各为$n_i$个
随机变量$X$是有限或无限可数样本空间$S$到实数的函数
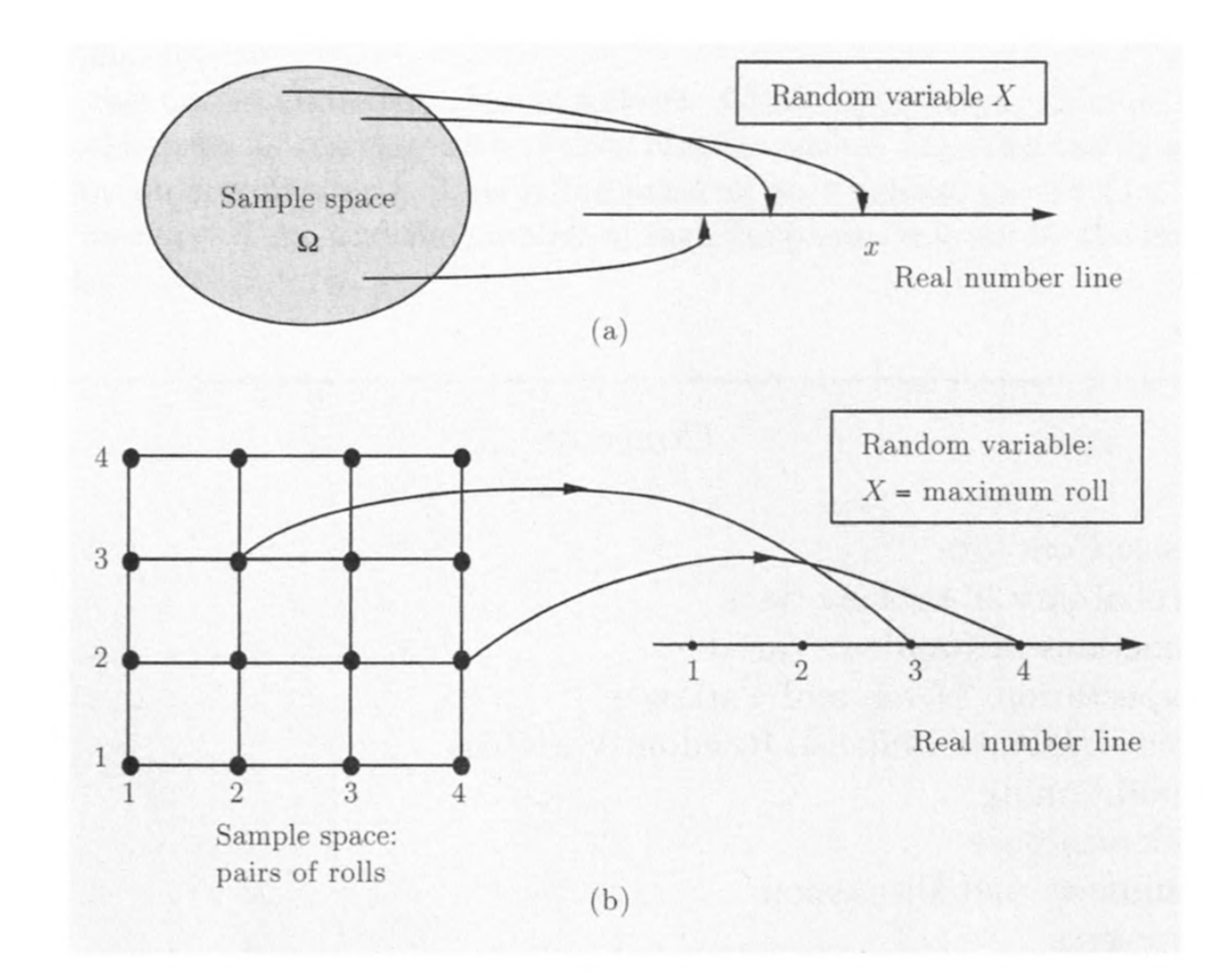
对于随机变量$X$和实数$x$,定义事件$X=x$为${s\in S,X(s)=x}$,因此
we will use upper case characters to denote random variables, and lower case characters to denote real numbers such as the numerical values of a random variable.
对于随机变量,函数$p_X(x)=\Pr{X=x}$为$X$的概率质量函数PMF
特别的,对于连续随机变量也称为概率密度函数PDF
归一化条件为
所以$f_X(x)$可以看成单位长度的概率
可以把这两种函数整合成一个函数
即为累积分布函数CDF(cumulative distribution function)
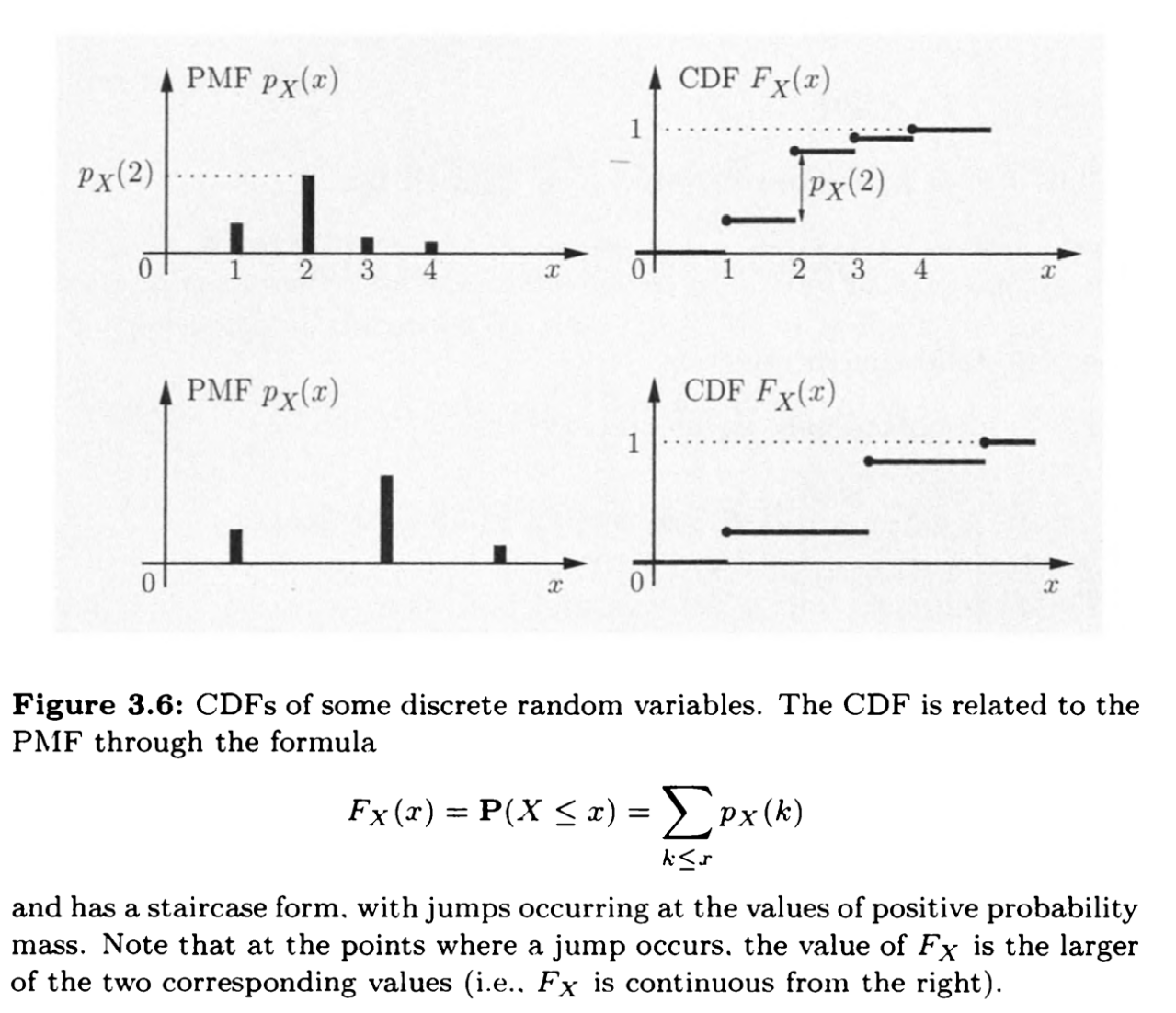
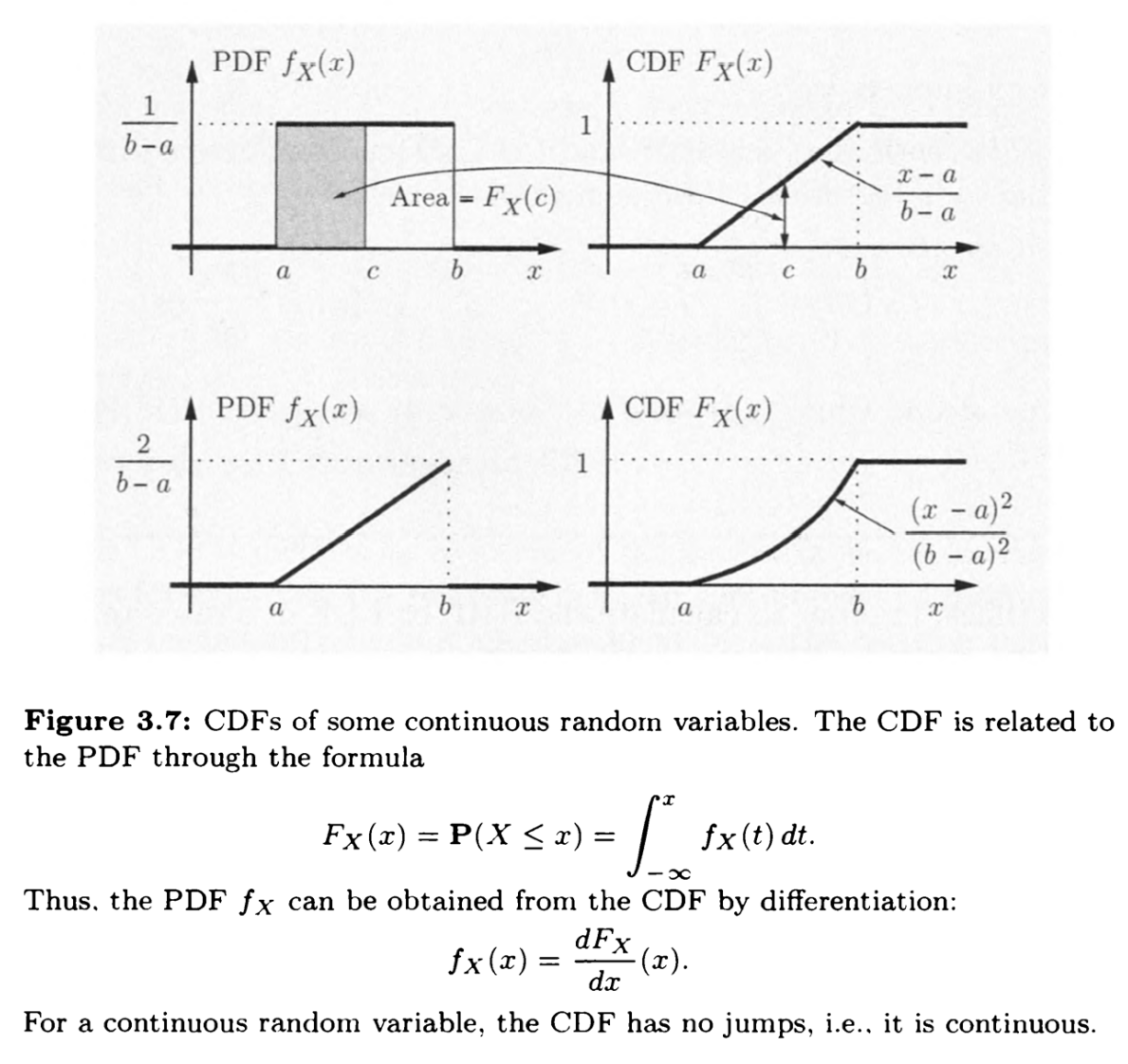
可以类比积分上限函数,通过差分和求导可以还原
若有若干个随机变量,即为多维随机变量
则有联合PMF
为$X$与$Y$的联合概率密度函数,性质同理,
如边缘$\rm PMF$
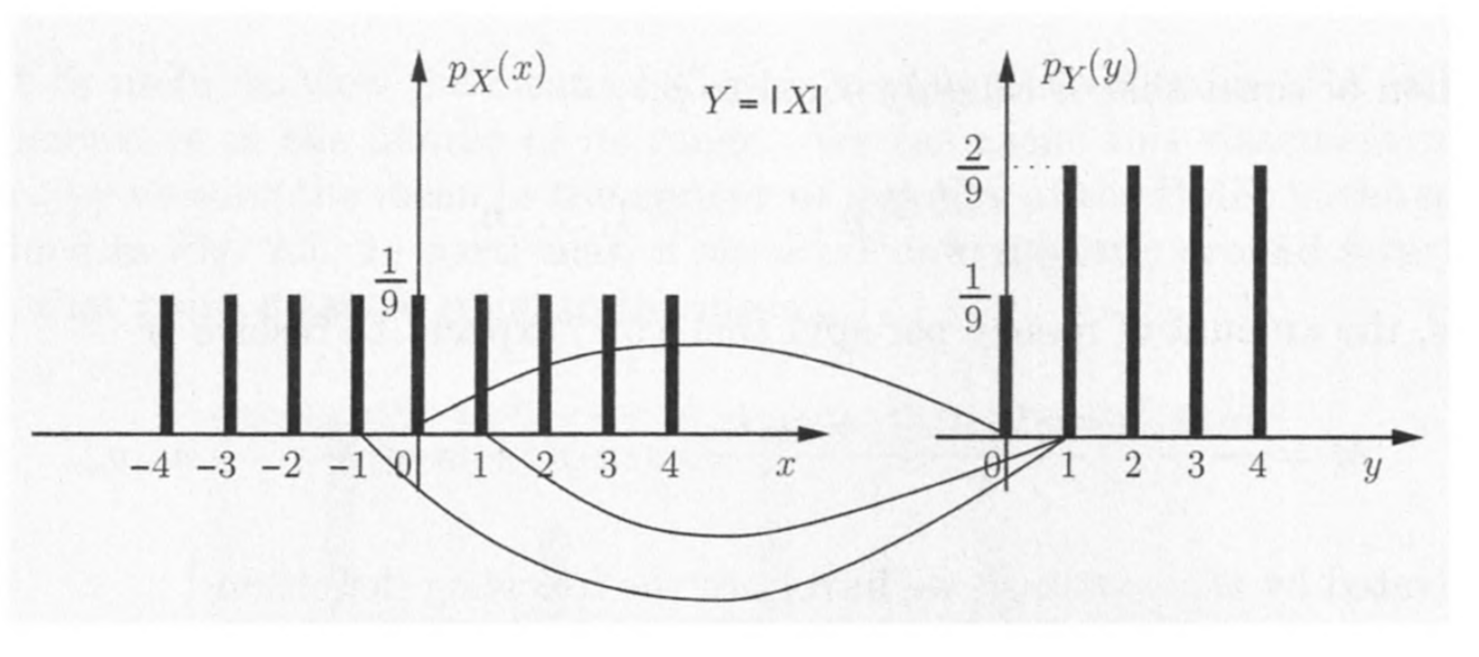
设$(X,Y)$的联合分布为$F(X,Y)$则
为随机变量$X$的边缘分布函数
为边缘密度函数
利用定义可以求$Z=g(X,Y)$的分布
从而有
对于连续的随机变量
期望的线性性质
若相互独立,使用期望的定义得
对于连续的随机变量
若相互独立
标准差
随机变量使用概率密度函数描述,概率密度函数具有一个特性,称为 矩 Moment,矩是随机变量幂的期望。我们重点关注两种矩:
对于矩阵$\tilde{X}(d_1,d_2)$,其均值为
线性性质
若对于一切$x,y$
则称两随机变量相互独立
则有
类比有
相关系数
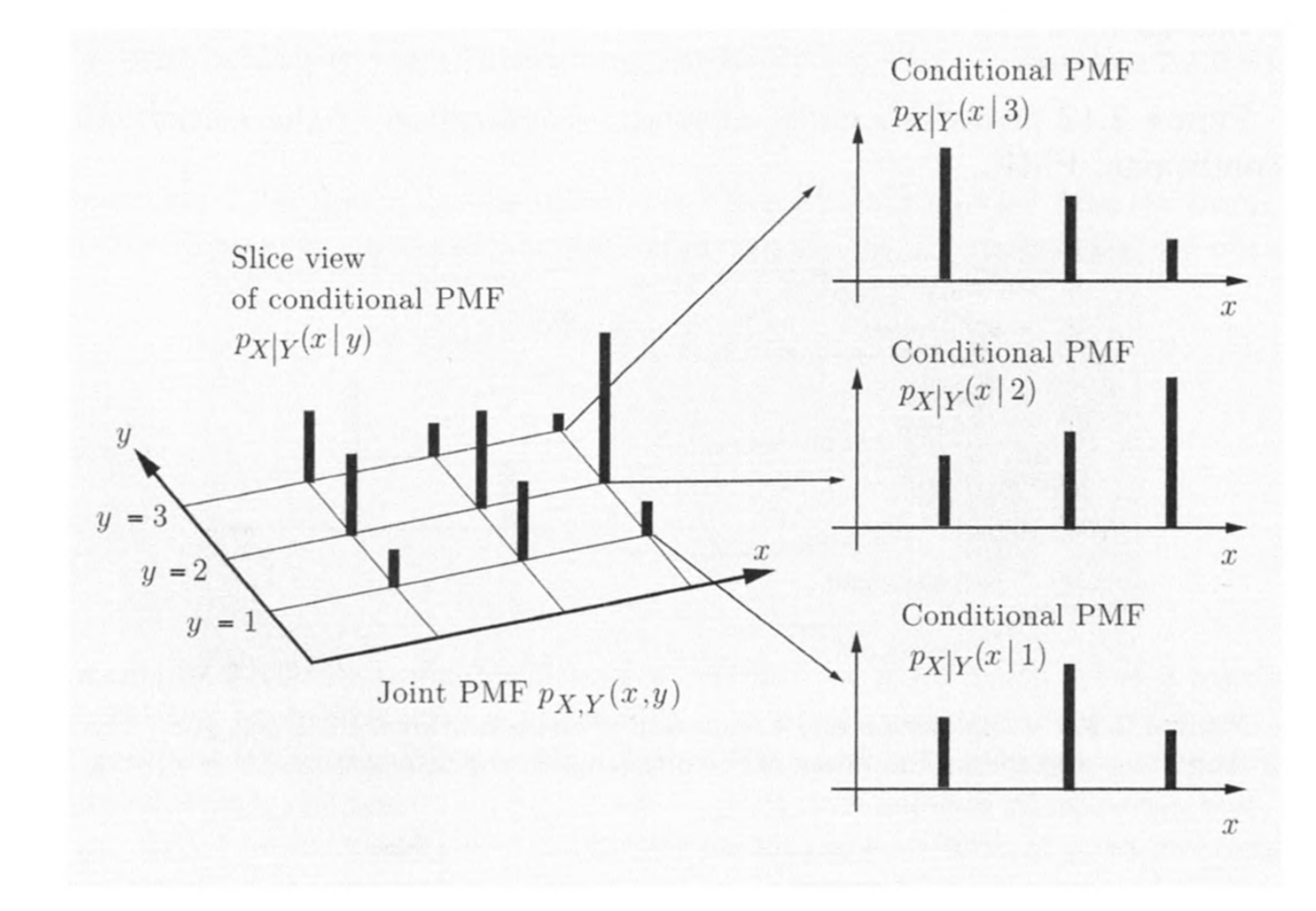
conditional PMF

可以将A推广为一个随机变量
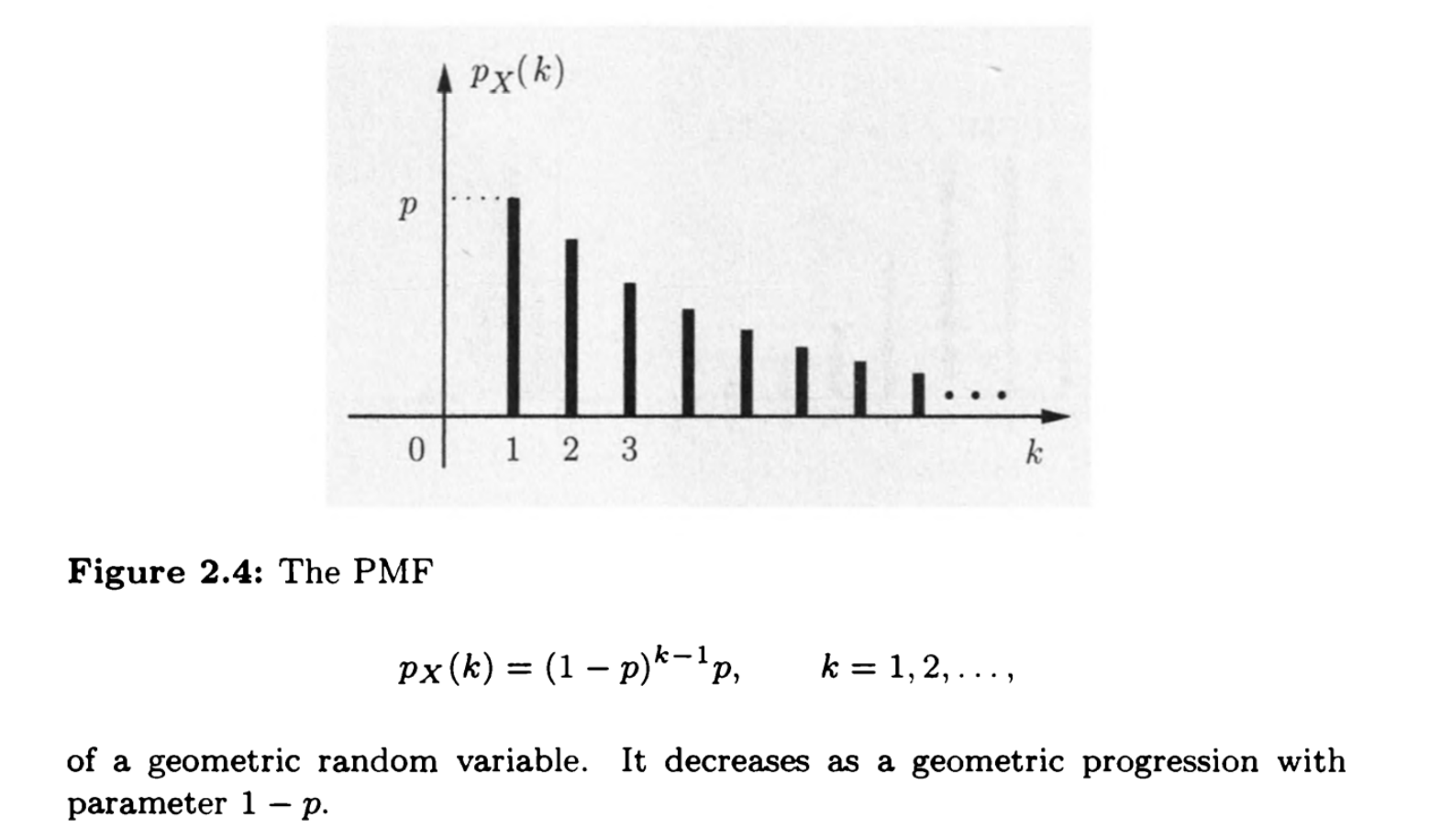
前面一直没有成功直到第n次才成功
区别于国内表达,组合数记为
读作$n$取$k$
在某段时间内事件发生的概率为
则$t=0\to1$发生的次数可以表示为
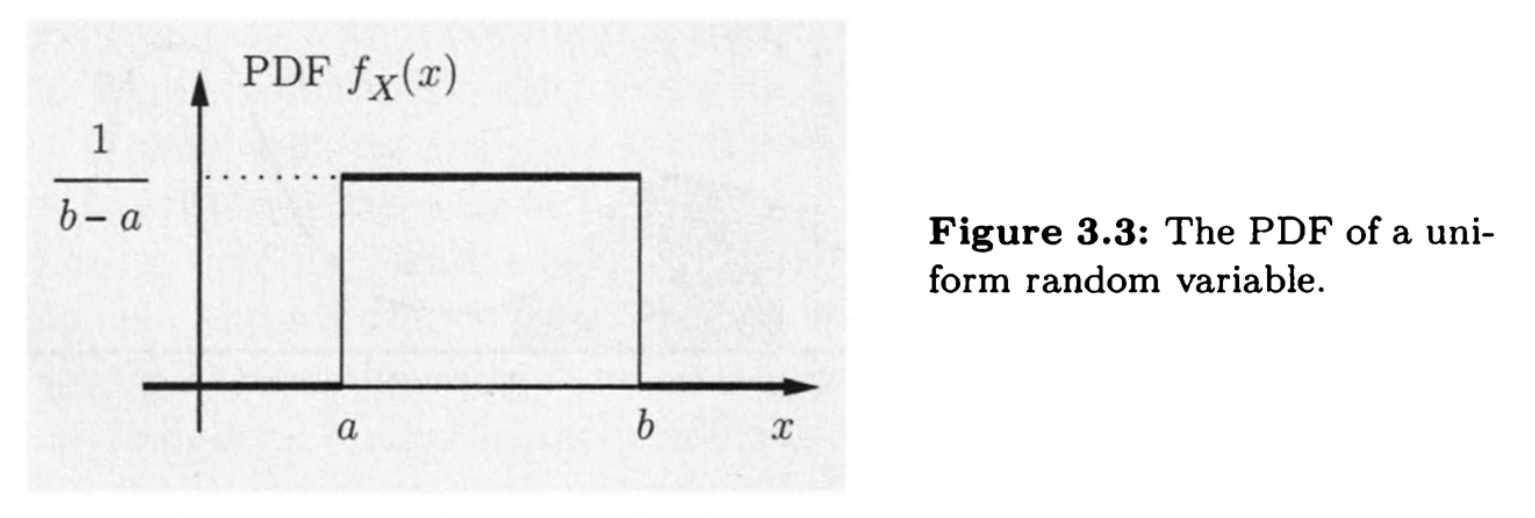
记为$X\sim U(a,b)$
则可以写出分布的期望和方差
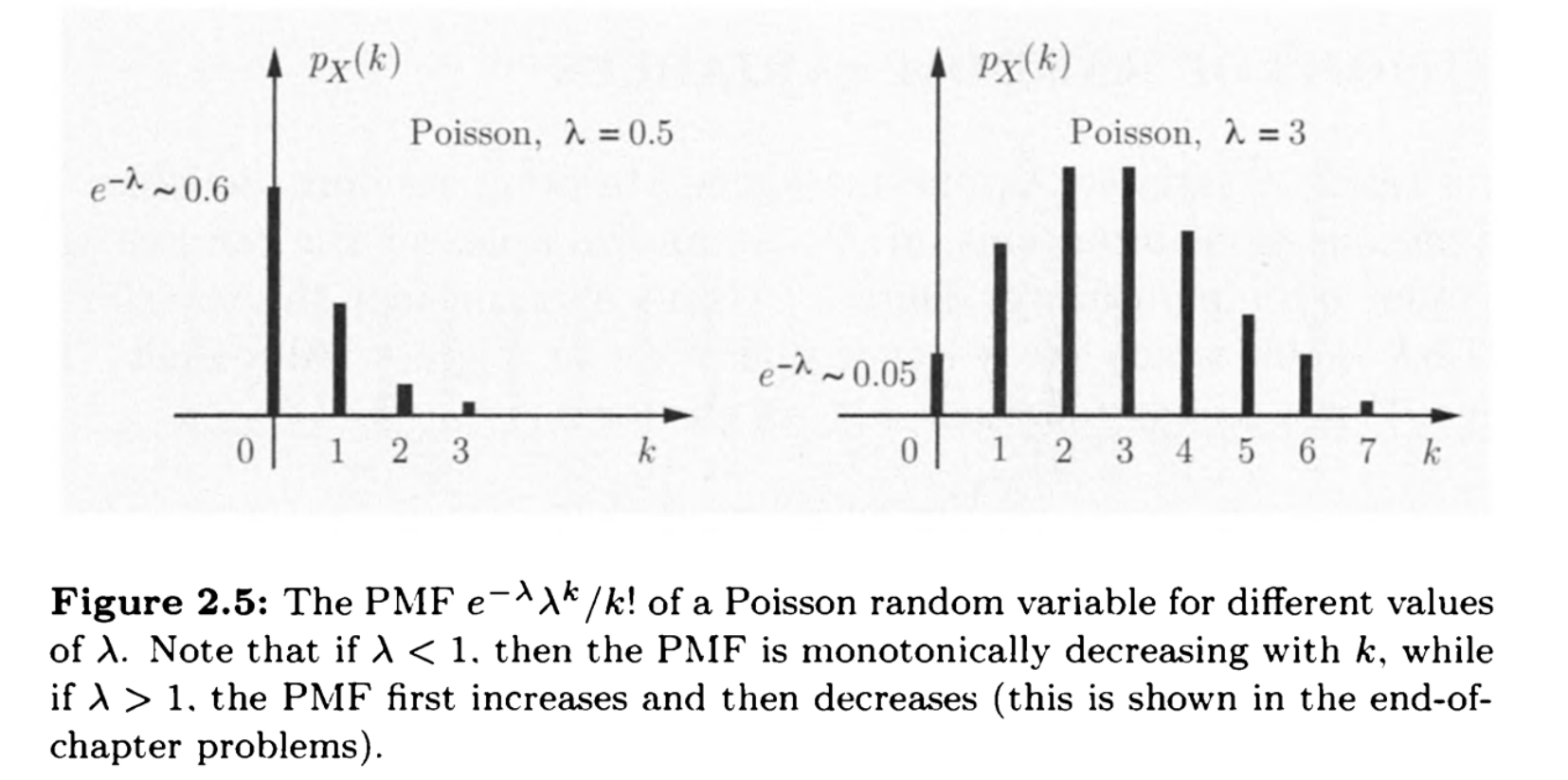
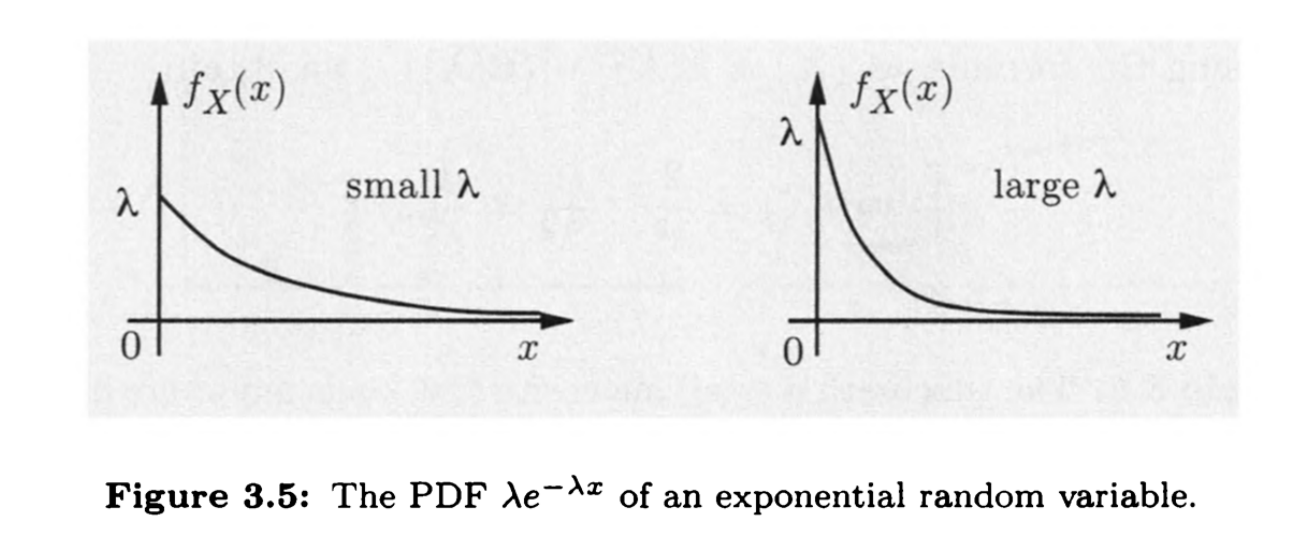
记为$X\sim E(\lambda)$
其中$\lambda$是参数可以用来调控均值,这个模型用途很广
类似与几何分布的情况,只不过用到了泊松分布的假设
自然界许多现象都遵循 正态分布 Normal Distribution。正态分布又称为 高斯分布 Gaussian Distribution (纪念著名数学家卡尔·弗莱德利希·高斯),其表达式如下:
记为$X\sim N(\mu,\sigma^2)$,若$\mu=\sigma=1$则为标准正态分布
可以利用标准正态分布函数来计算概率
可加性
则称$u_p$为标准正态分布的$p$分位数
$X_i$服从同一分布,则
$\beta_s(X)<0$为左偏,左侧有较长的尾部,反之同理
峰度和正态分布比较
用均值标准化
切比雪夫不等式,若$E(X^2)<+\infty$
马尔可夫不等式,若$E(|X|^p)<+\infty$
样本均值
或者
若$X_i$服从标准正态,则$U$服从自由度为$n$的$\chi ^2$分布
样本方差
$\overline X$和$S^2$相互独立
可加性
若$X\sim N(0,1),Y\sim \chi^2(n)$
用样本矩来估计总体矩
最大化
无偏
渐近无偏
相合
无偏或渐近无偏且
枢轴变量
若方差已知,双侧
单侧
方差未知,用样本来估计
方差置信区间
可得
若方差未知则