网络整体架构
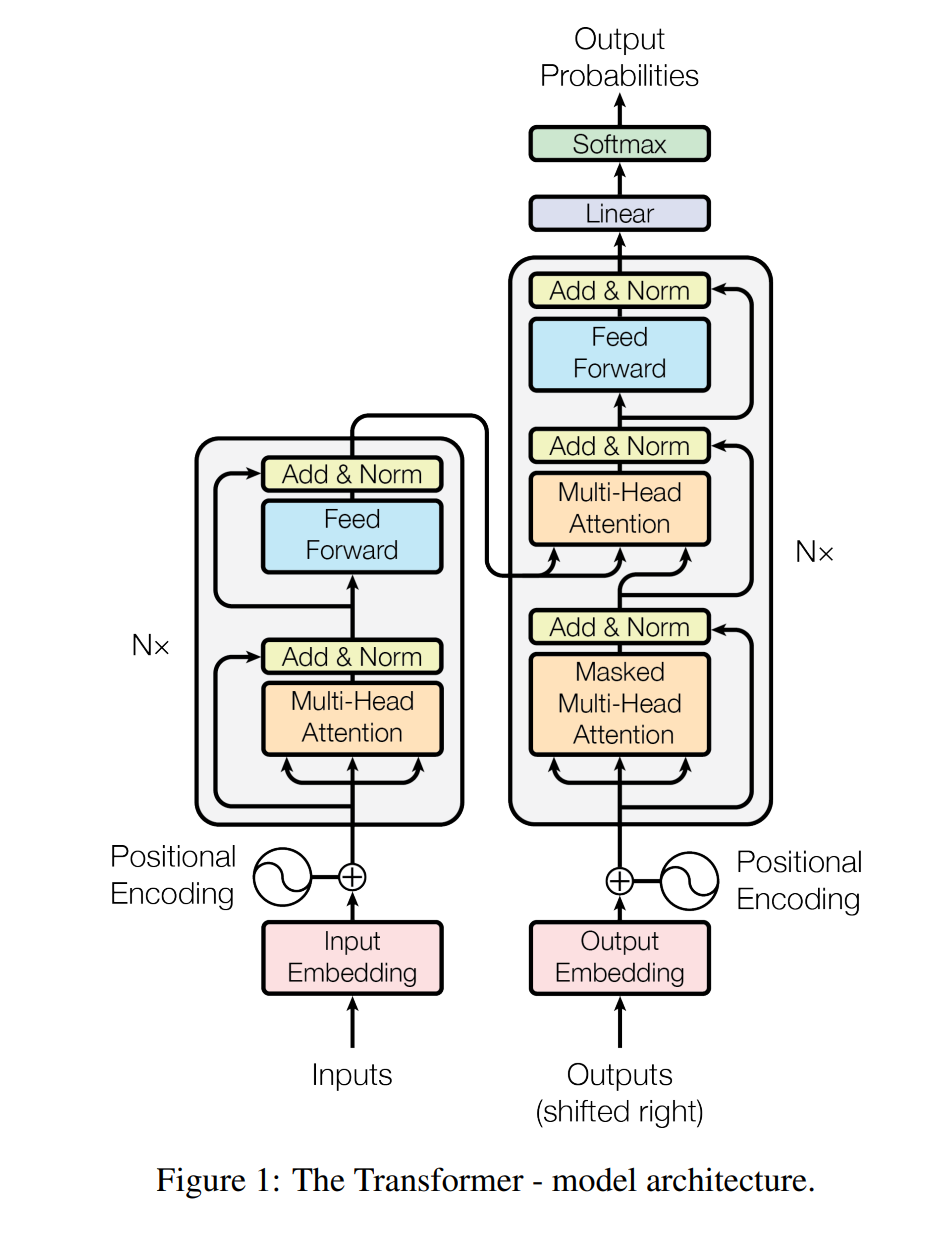
Encoder
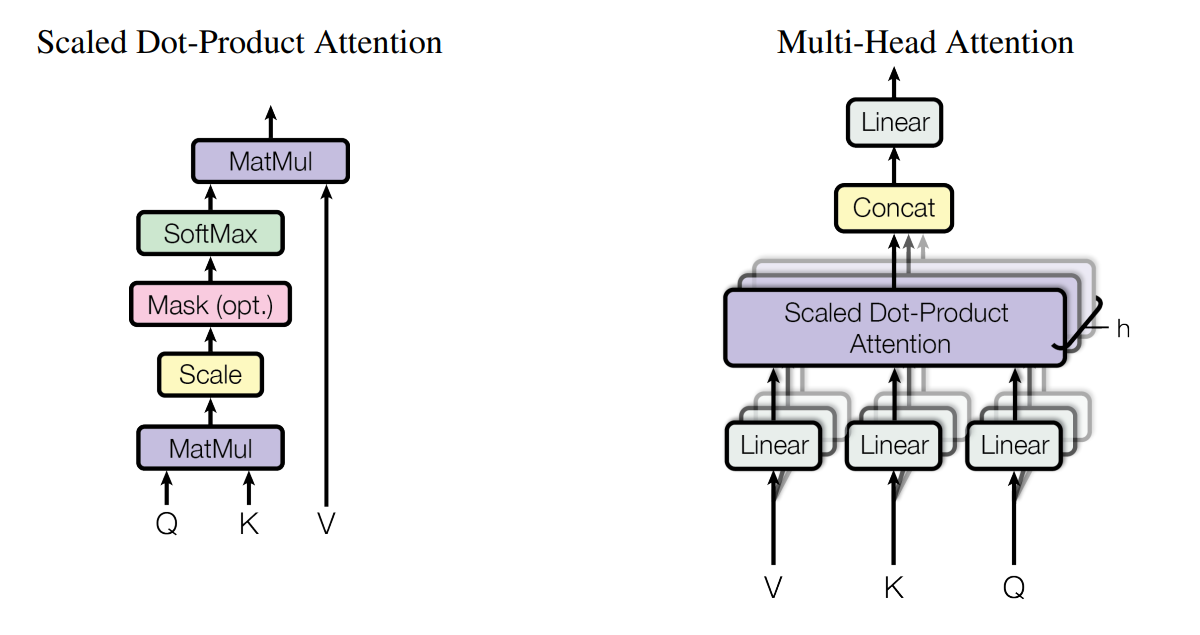
注意力机制
何为自注意力,就是输入为自己
利用$FC$层编码信息后
利用余弦相似度进行判断
利用$\text{softmax}$得到概率分布,最后得到输出
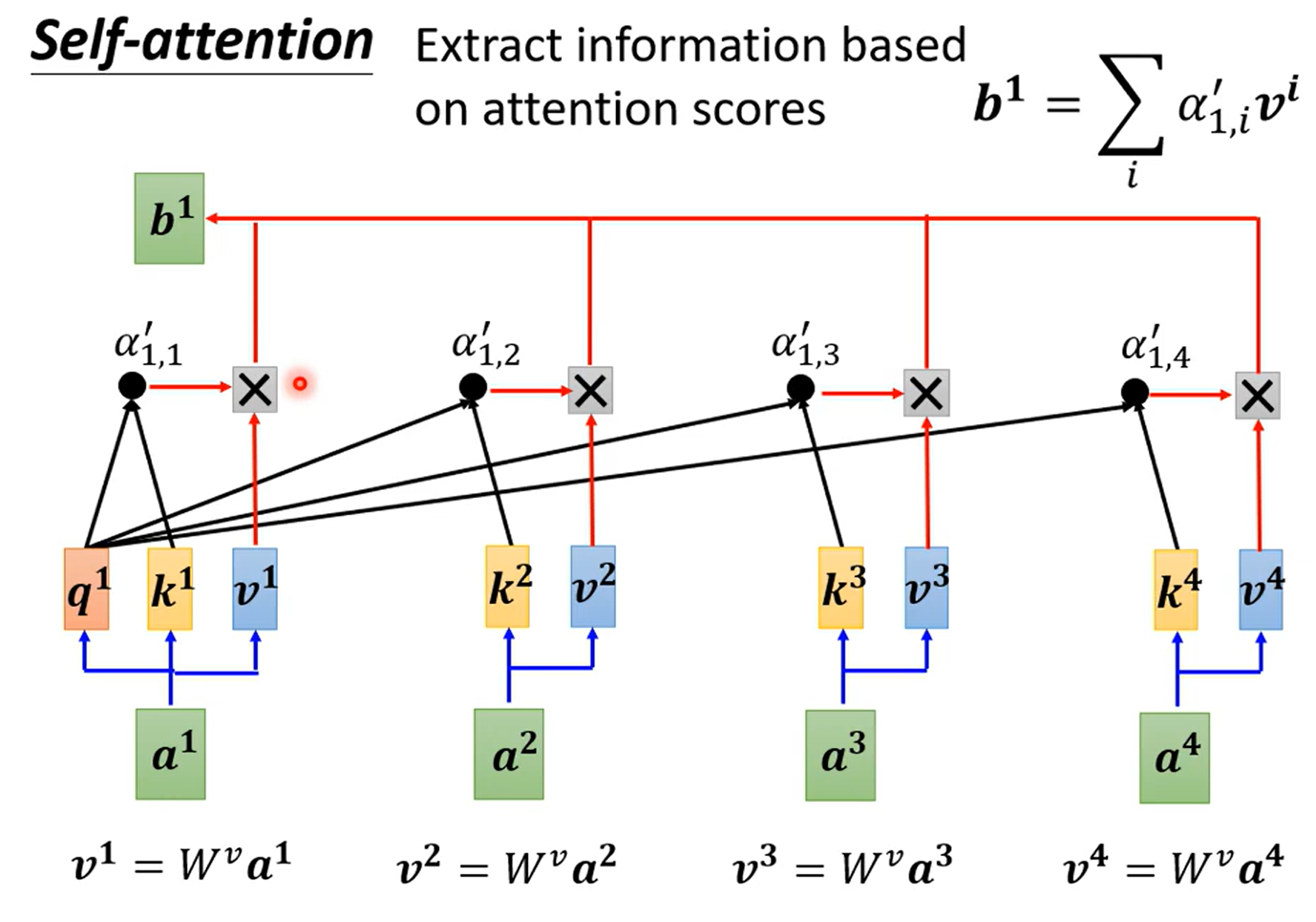
输出为类似加权平均的形式,是$Q$的编码结果
其中$W$为权重矩阵,通过训练得出
多头
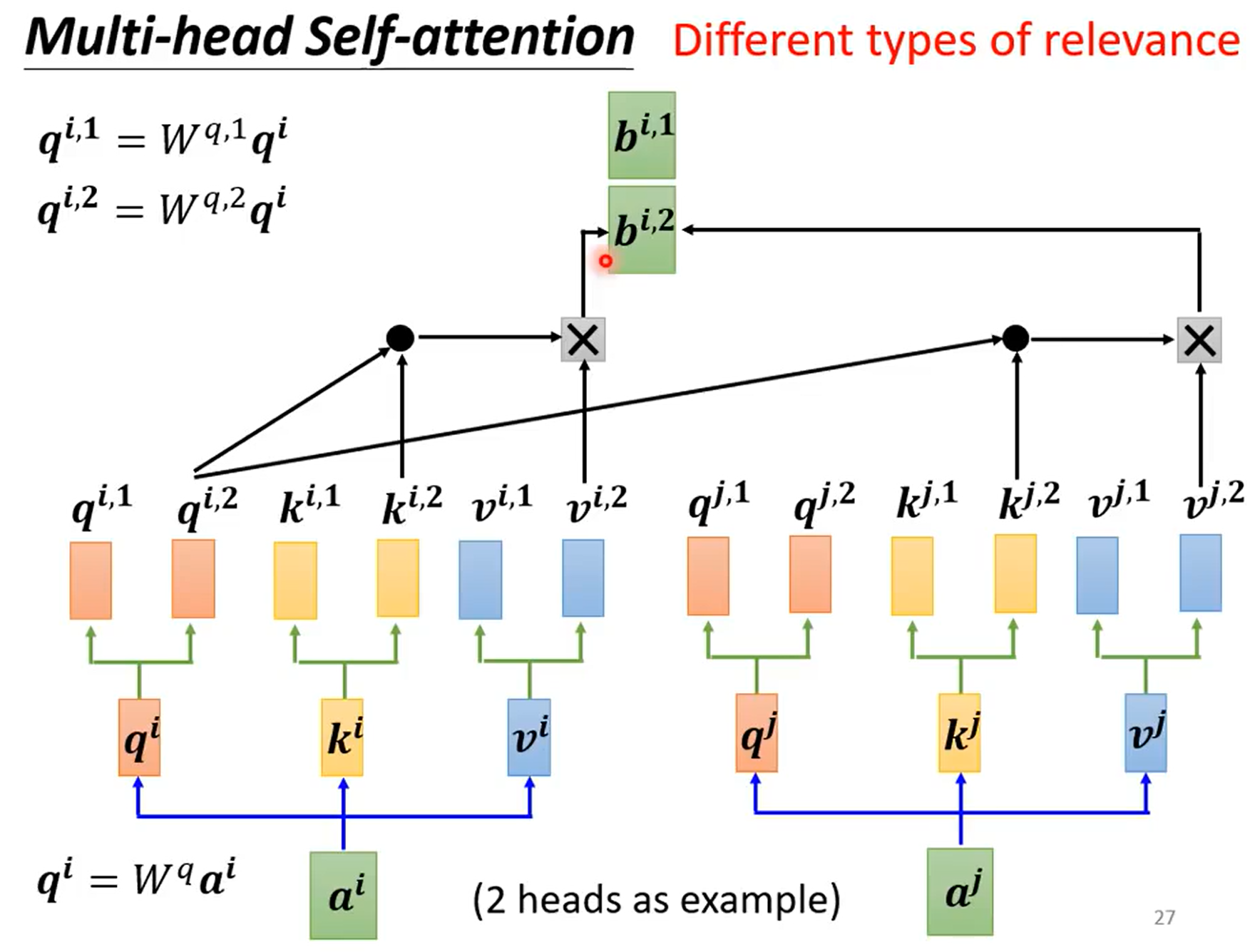
相关性也有不同的种类
利用$FC$将数据进行特征分离,并行$h$头
位置编码
为了学习序列的位置信息,使用位置向量$e^i$
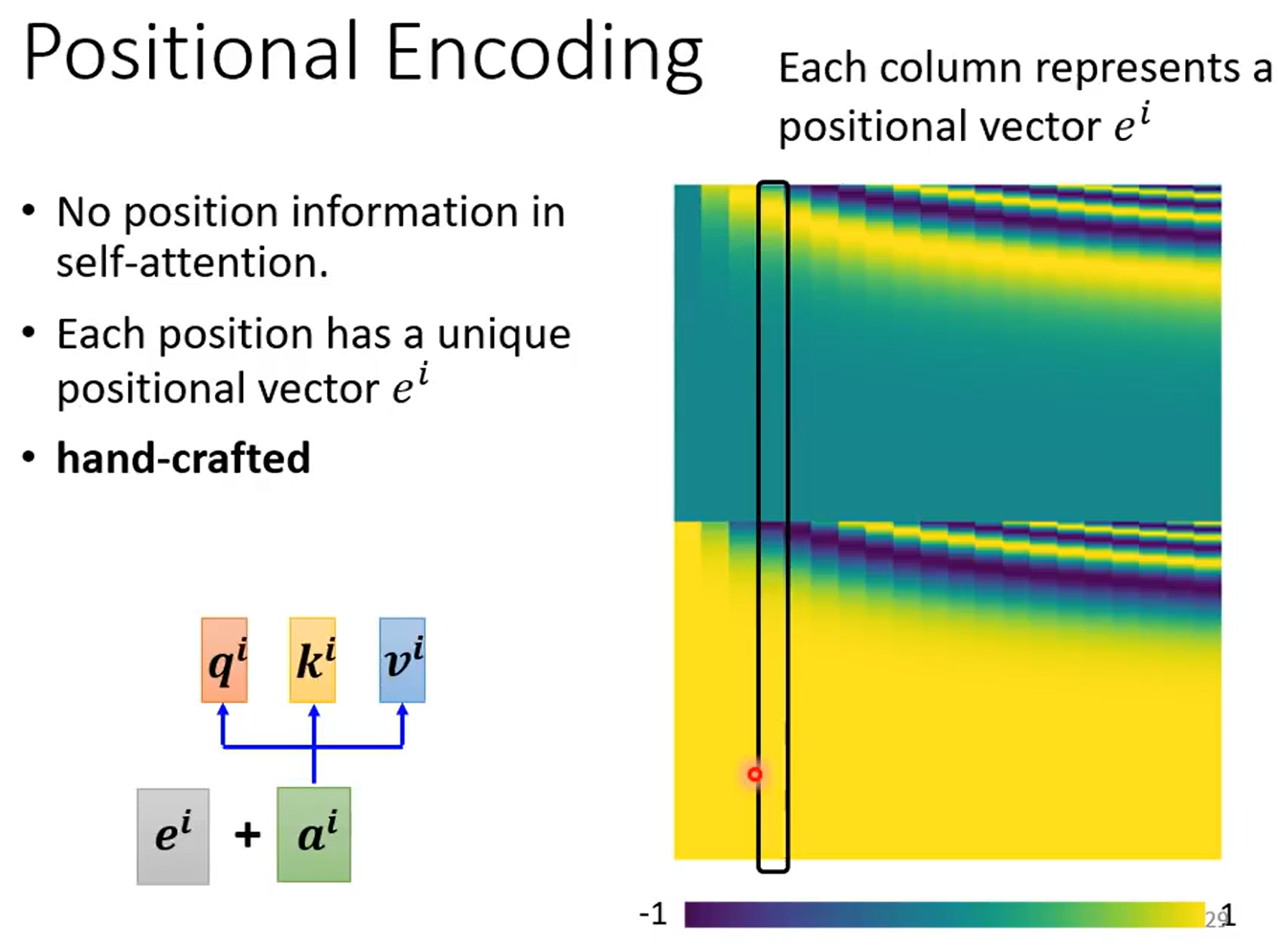
手工设定,或者直接学习
Layer Norm
对不同的特征计算
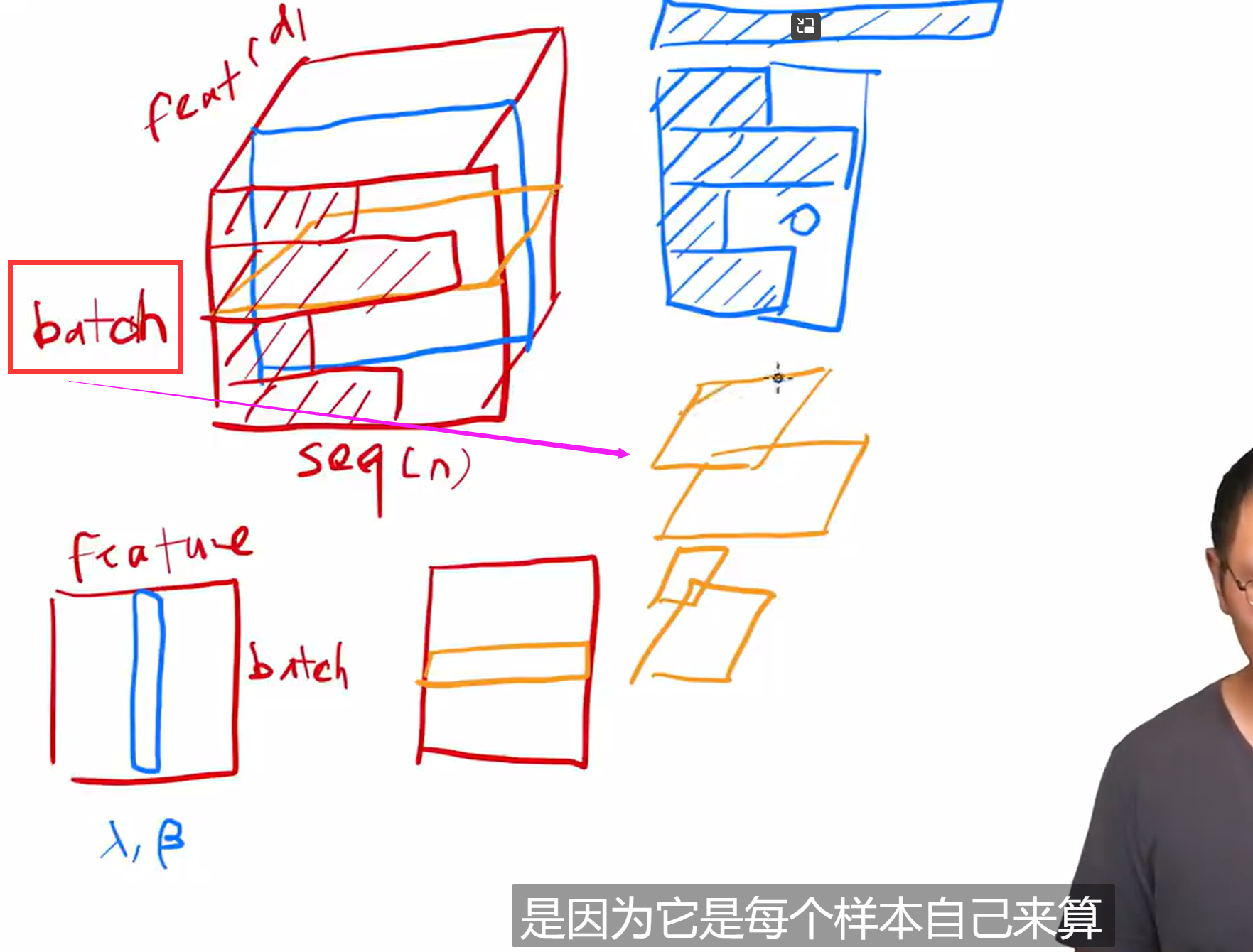
常常对最后一个维度进行,对多头即为
残差连接
训练的过程中始终保留了原始信息,还增加了网络中获取的新知识
$F(x_l,W_l)$为残差
由损失函数的梯度计算结果可知,网络在进行反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度弥散(梯度消失)问题(即便中间层矩阵权重很小,梯度也基本不会消失)
其中前馈层为
这个前馈层的作用是引入非线性映射$(\rm ReLU)$,通过两个线性变换和激活函数,对输入进行复杂的非线性变换。这有助于模型学习更加复杂的函数关系。在 Transformer 模型中,每个位置都有独立的前馈层,这使得模型能够在不同位置学习不同的表示。
decoder
将Encoder编码的信息进行解码转换
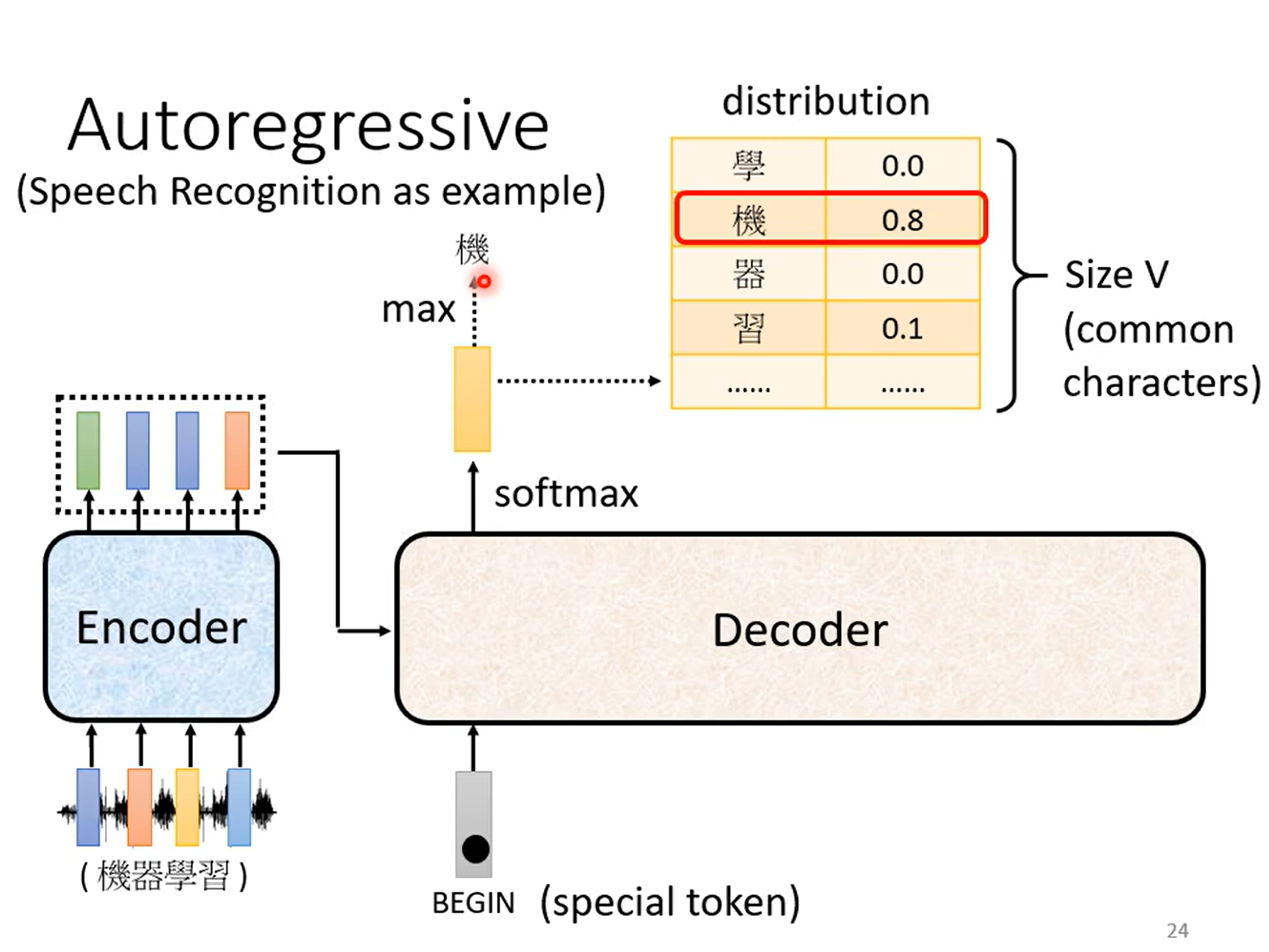
输入用$\text{One Hot}$进行编码,向量大小为输出集的大小
Masked自注意力
只把过去的output来作为$\text{keys,values}$
训练时每次把未来的输入$\rm Mask$一下
每次只query$t$时刻的输出,同时decoder放入$1\sim t$的输出
从而得到$t+1$时刻的输出
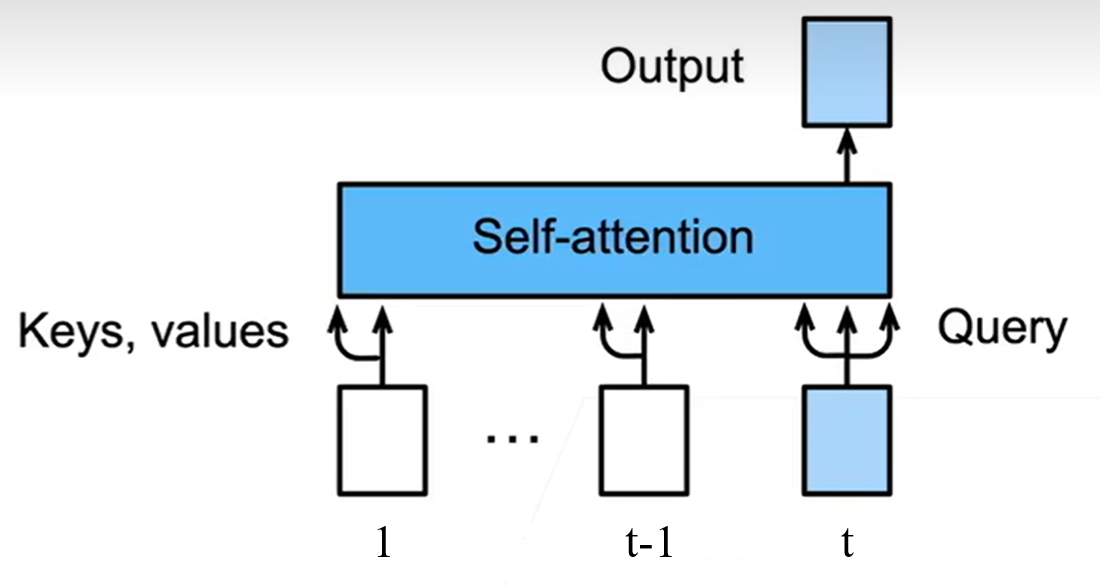
cross-attention
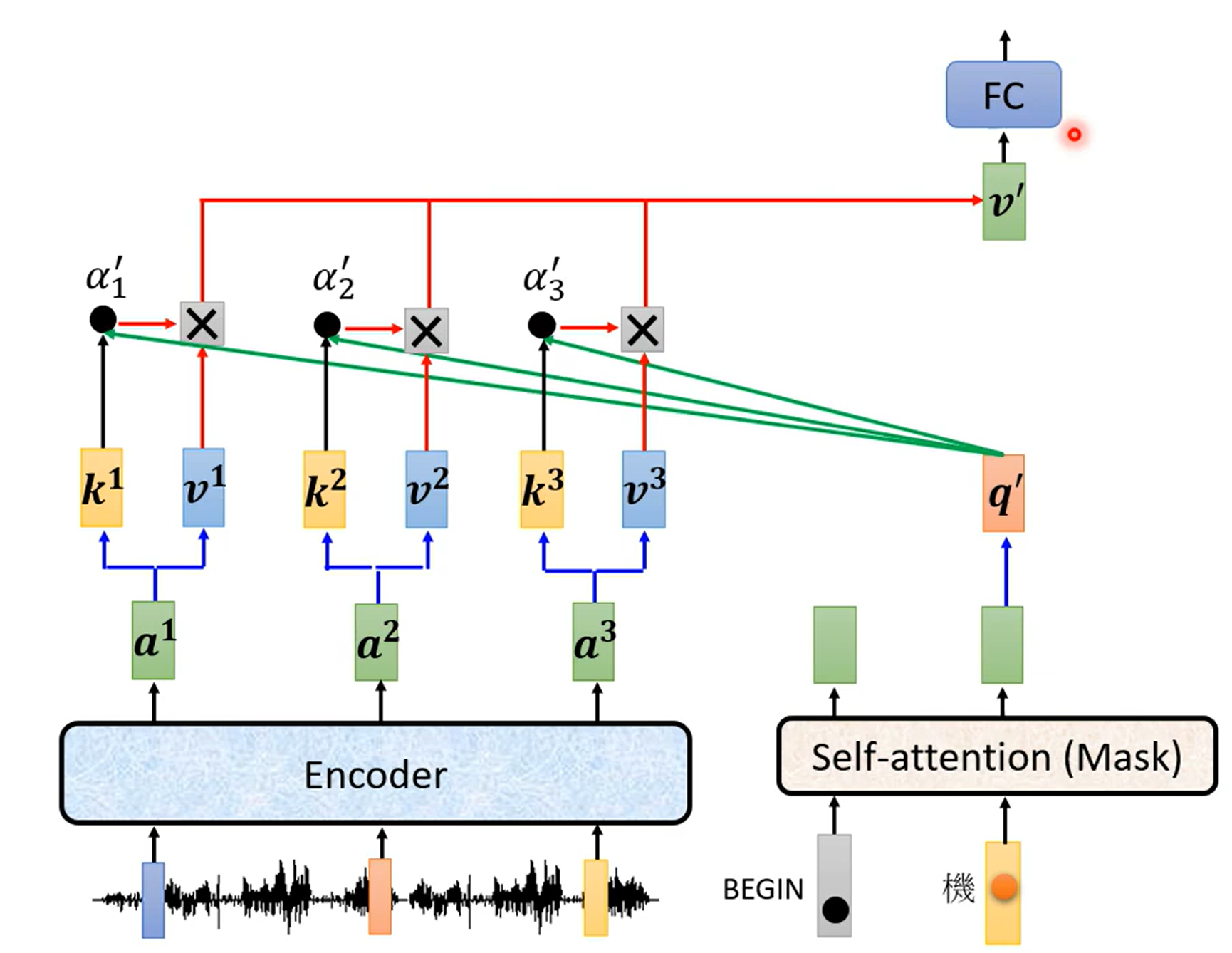
$K,V$来自Encoder而$Q$来自Decoder