回归模型
输入向量
模型
其中$\epsilon$为误差,不可避免
回归函数(regression function)为理想目标
$X$表示抽象特征$x$为具体值
需要准确根据所有数据选取模型的复杂度
线性模型
几乎不可能正确,但很可能是最佳的一部分
相关系数为
计算标准差的平方(方差)为
标准差为
其中$\sigma^2=\text{Var}(\epsilon)$
因为$x_i$为人为给定量,$y_i$为测量值,存在误差
若样本无穷大,有总体回归线
由方差的性质得到
SE(Standard Error)为标准误差

1、均方差就是标准差,标准差就是均方差
2、方差 是各数据偏离平均值 差值的平方和 的平均数
3、均方误差(MSE)是各数据偏离真实值 差值的平方和 的平均数
4、方差是平均值,均方误差是真实值

RSE:Residual Standard Error
RSS:Residual Sum of Squares
由误差导致的真实值和估计值之间的偏差平方和
置信区间
Confidence Intervals
有$95\%$的概率使得最佳值在区间内(根据数据的不同)
多元
若一个量变化,其余量固定不变,不相关(常常不符合事实)
但有一些很有用,能够看出某个量的影响
展开后求导可得
其中$X$代表$n$个样本
对于
相关
若两个量相关则
对于多元模型,可以引入乘积项
优化
最小化方差
$\hat{f}(x)$为所估计的函数
但每个值不一定都有
取测试数据集计算准确度,评估模型好坏
可以引入非线性项来改进模型
分类模型
考察$x$的邻域$\mathcal{N}(x)$,如扩展到$10\%$的数据
但对高维数据范围太大失去了局部信息,效果不好
分类器$C(X)$,考虑条件概率
分类结果为
用正确率来衡量结果
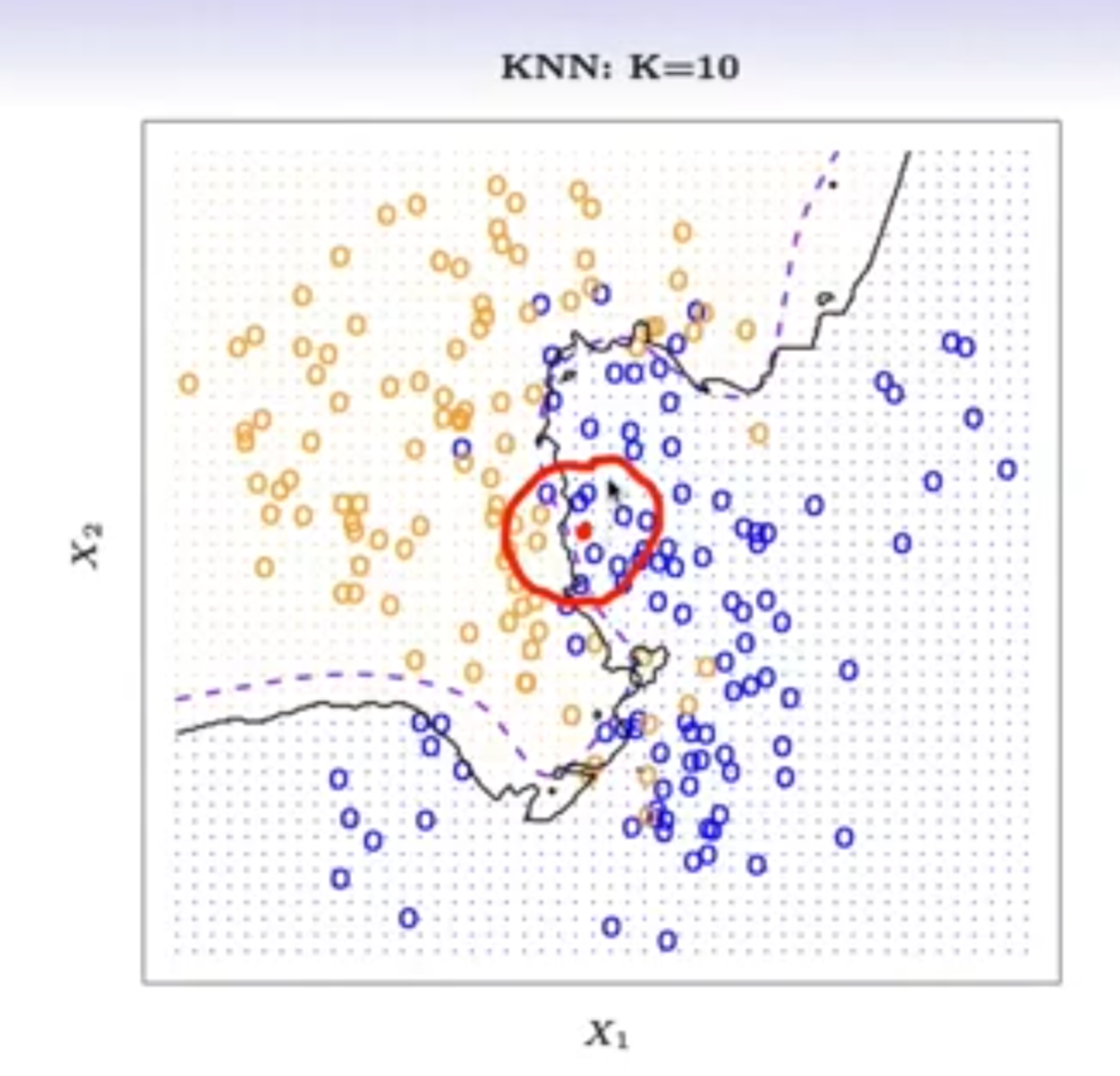
可使用$\rm Nearest-neighbor$,如找十个看哪种最多
Logistic
逻辑斯谛回归
这是一种广义线性模型,利用最大似然函数估计误差
随机抽小球,取得一个样本
我们认为概率最大的情况就是这个结果,从而